一、Solr 概述
1.1 Solr 简介
- Solr:
Solr 是一个高性能,采用 Java5 开发,基于 Lucene 的全文搜索服务器。同时对其进 行了扩展,提供了比 Lucene 更为丰富的查询语言,同时实现了可配置、可扩展并对查询性 能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。 - 下载:Solr 是 Apache 下的一个开源项目,由于是基于 Lucene 的一个实现产品,因此将 Solr 放在 Lucene 项目当中。可以在官方网站的历史版本中下载我们需要的版本。此处以4.10.2为例
- 目录结构
- contrib/dist:存放Solr 插件依赖的 jar 包
- example:存放Solr内置实例
- Solr 目录用来存放 Solr 的 Core,主要包含索引和配置文件。
- solr-webapp 目录中管理者 Jetty 运行的 Solr 服务去程序。
- Webapps 目录中的 solr.war 为 solr 服务的文本应用程序。
- start.jar:内置 Jetty 服务器,可以直接运行Solr 服务
1.2 运行 Solr 服务
Solr 实际上是一个 web 服务器应用程序,因此要启动 Solr 需要文本服务器,而在 Solr 实例代码中已经直接集成了 Jetty 服务器,我们可以直接使用, 也可以单独配置和使用 Tomcat 服务器来启动 Solr 服务。
-
启动 Solr 服务的方式
-
使用 Solr
内置的 Jetty 服务器启动 Solr-
使用内置的 Jetty 来启动 Solr 服务器只需要在 example 目录下,执行 start.jar 程序即可,我们可以直接执行命令:
$ java –jar start.jar -
当服务启动后,默认发布在
8983端口,所以可以访问该端口来访问 Solr 服务。
-
-
将 Solr 部署到 Tomcat 中
-
在 Tomcat 中部署 Web 服务,将 solr-4.10.2/example/webapps/solr.war 复制到自 己的 tomcat/webapps 目录中,解压后移除war包(因为每次服务器重新启动后,会被覆盖)。
$ cd /home/silhouette/solr-4.10.2/example/webapps $ cp solr.war /home/silhouette/apache-tomcat-8.5.38/webapps/ $ unzip solr.war -d solr -
解压后Solr还不能直接访问,因为缺少相应的jar包,所以需要将 Solr 用到的 jar 包拷贝到项目的 lib 目录下
$ cd /home/silhouette/solr-4.10.2/example/lib/ext $ cp * /home/silhouette/apache-tomcat-8.5.38/webapps/solr/WEB-INF/lib/ $ cd /home/silhouette/solr-4.10.2/example/resources $ cp log4j.properties /home/silhouette/apache-tomcat-8.5.38/webapps/solr/WEB-INF/classes -
拷贝Solr 的索引目录。
-
将 Solr 用到的 jar 包拷贝到项目的 lib 目录下或者只想所在目录,在启动前还需要设置 solr.solr.home 启动参数,在 catalina.bat 文件添加配置:
$ mkdir solr_home $ cd solr_home $ cp -r ../example/solr ./ $ vim catalina.sh $ set "JAVA_OPTS=-Dsolr.solr.home=/Users/silhouette/software/apache/solr/solr-4.10.2/solr_home/solr" ####Linux 环境下 $ export "JAVA_OPTS=-Dsolr.solr.home=/Users/silhouette/software/apache/solr/solr-4.10.2/solr_home/solr" -
启动 Tomcat 则 Solr 的服务器发布就完成了。
-
-
1.3 Solr 管理界面
solr 服务器管理界面可以查看系统状态、solr设置、分词检测、查询索引、增减core、查看日志等
-
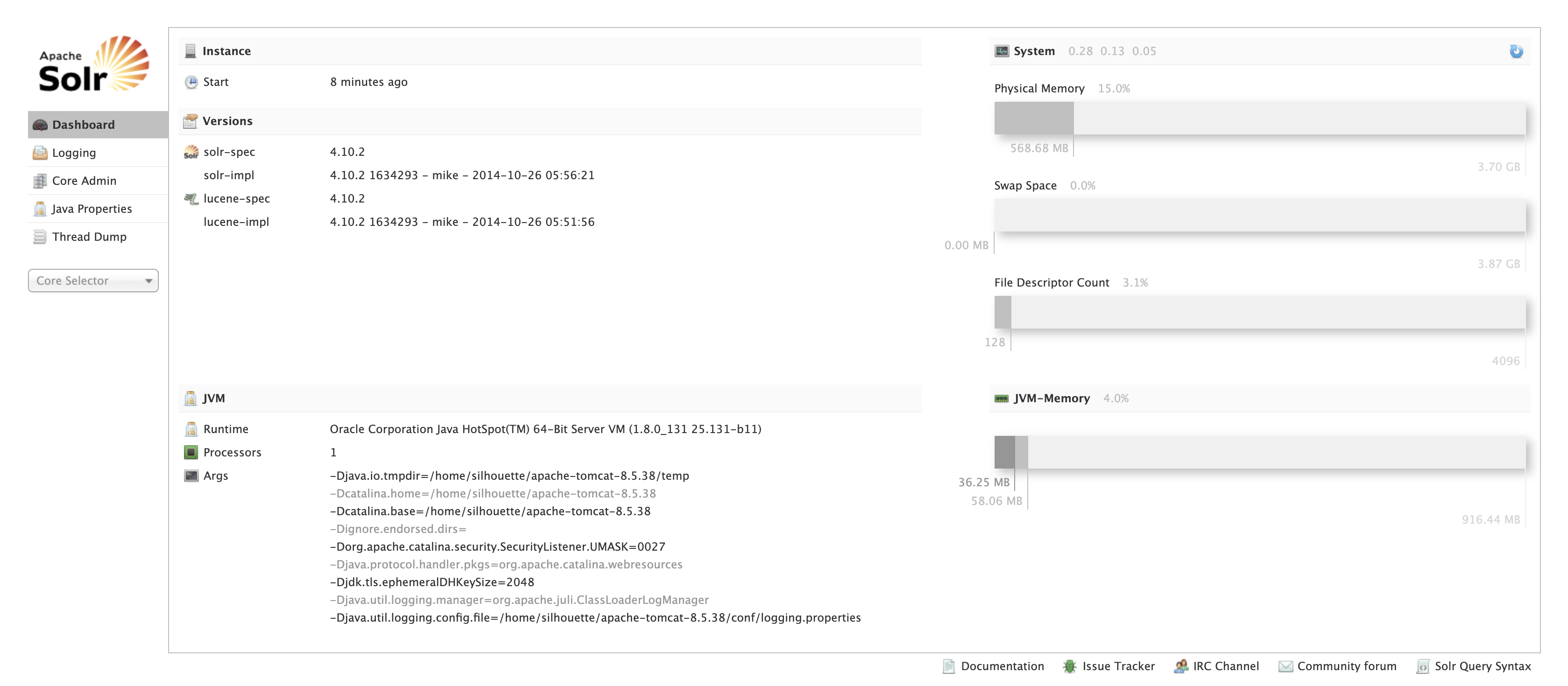
DashBoard(仪表盘)
-
查看到solr运行时间、solr版本,系统内存、虚拟机内存的使用情况
-
-
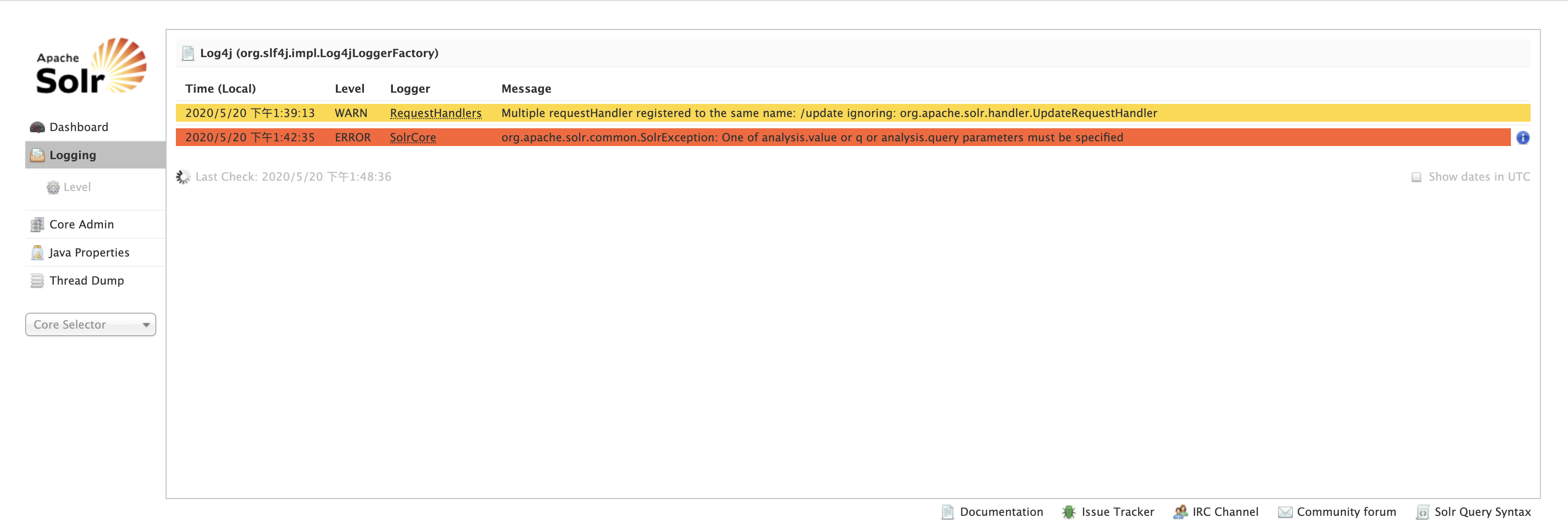
Logging(日志)
-
显示solr运行出现的异常或错误
-
-
Core Admin
-
在 Solr 中,每一个 Core,代表一个索引库,里面包含索引数据及其信息。Solr 中可以 拥有多个 Core,也就同时管理多个索引库!就像在 MySQL 中可以有多个 database 一样。
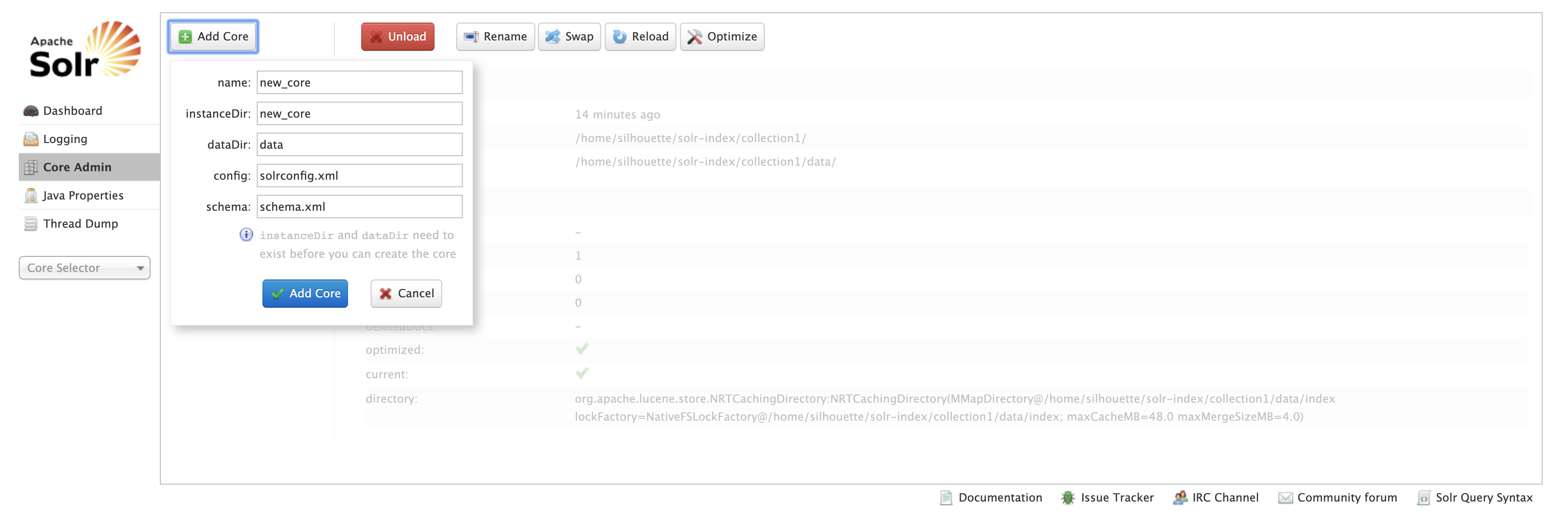
- name:给core起的名字;
- instanceDir:与我们在配置solr索引库时的solr_home里新建的core文件夹名一致;
- dataDir:确认Add Core时,会在new_core目录下生成名为data的文件夹
- config:new_core下的conf下的config配置文件(solrconfig.xml)
- schema: new_core下的conf下的schema文件(schema.xml)
Tips:可以直接拷贝本地的Collection1然后重命名,再修改core.properties文件即可达到相同效果
-
-
Java Properties
- 可查看到java相关的一些属性的信息
-
Core Selecter(core选择器)
-
需要在Core Admin里添加了core后才有可选项,这里以默认的collection1为例。

-
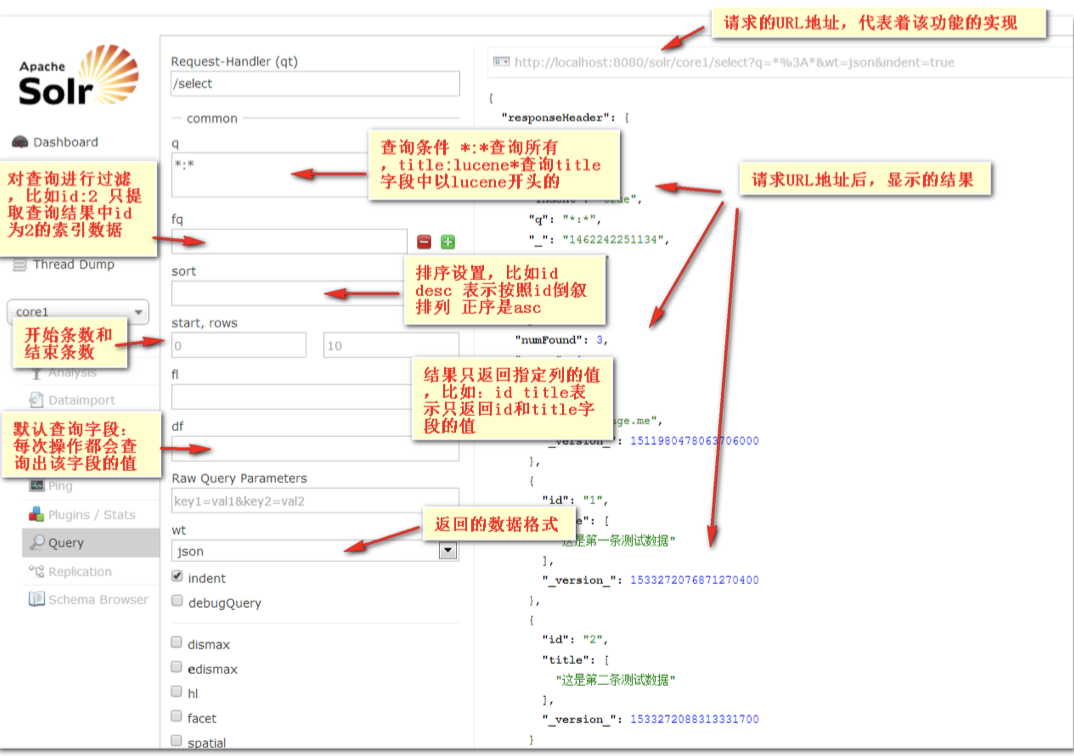
通过 Solr 管理界面查询索引数据
-
1.4 Solr中的Core详解
-
Core 的概述:在Solr 中一个 core就是一个索引库,里面包含索引信息和配置文件。
-
目录结构
-
conf:配置文件目录
-
schema.xml:字段及字段约束信息,如:字段数据类型、字段是否索引、是否存储、是否分词等
-
通过
Field字段定义字段的属性信息<!-- 配置Field,就是配置在Solr中可以使用的字段名称。属性及含义: name:字段名称 【_version_、_root_是Solr系统使用的】 type:字段类型,指向的是本文件中的<fieldType>标签 indexed:是否创建索引 stored:是否被存储 multiValued:是否可以有多个值,如果字段可以有多个值,设置为 true --> <fieldType name="string" class="solr.StrField" sortMissingLast="true" /> -
通过
FieldType字段指定数据类型<!-- name:字段类型的名称,可以自定义,<field>标签的 type 属性可以引用该字段,来指定数据类型 class:字段类型在 Solr 中的类。StrField 可索引不可分词。TextField 字段可索引,可以分词, 所以需要指定分词器 <analyzer>:这个子标签用来指定分词器, --> <fieldType name="text_general" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>-
配置使用IK分词器<!--先将IK分词器的jar包放入项目的lib目录中--> <fieldType name="text_general" class="solr.TextField"> <analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="query" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
-
-
通过
dynamicField字段来定义动态字段<!--表示只要满足特定的规则就可以使用--> <dynamicField name="*_i" type="int" indexed="true" stored="true"/> -
通过
uniqueKey字段来配置唯一主键<!--Lucene 中本来是没有主键的。删除和修改都需要根据词条进行匹配。 而 Solr 却可以设 置一个字段为唯一主键,这样增删改操作都可以根据主键来进行。--> <uniqueKey>id</uniqueKey>
-
-
Solrconfig.xml:索引库的相关配置
-
通过
<lib/>标签来配置插件依赖的 jar 包<!-- 如果引入多个 jar 包,要注意包和包的依赖关系,被依赖的包配置在前面 这里的 jar 包目录如果是相对路径,相对于 core索引库 所在目录 --> <lib dir="../../../contrib/extraction/lib" regex=".*\.jar" /> <lib dir="../../../dist/" regex="solr-cell-\d.*\.jar" /> -
通过
<requestHandler/>标签来配置 Solr 处理各种请求(搜索/select、更新/update、等)的各种参数<!--主要参数: name:请求类型,例如:select、query、get、update class:处理请求的类 initParams:可选。引用<initParams>标签中的配置 <lst name="defaults">:定义各种缺省的配置,比如缺省的 parser、缺省返回条数 --> <requestHandler name="/select" class="solr.SearchHandler"> <lst name="defaults"> <str name="echoParams">explicit</str> <int name="rows">10</int> <str name="df">text</str> </lst> </requestHandler>
-
-
-
data:索引数据目录
-
Core.properties:core的自身属性。注意core的name属性与外面索引文件名保持一致
-
1.5 配置中文分词器与业务域
创建对应的业务域,需要制定中文分析器,具体创建步骤如下:
-
把中文分析器的
IKAnalyzer2012FF_u1.jar包添加到 solr 工程的lib目录下$ rz /home/silhouette/apache-tomcat-8.5.38/webapps/solr/WEB-INF/lib -
把扩展词典、配置文件放到 solr 工程的 WEB-INF/classes 目录下
$ cd /home/silhouette/apache-tomcat-8.5.38/webapps/solr/WEB-INF/lib $ mkdir classes $ cd classes $ rz ext_stopword.dic $ rz IKAnalyzer.cfg.xml $ rz mydict.dic
为了让分词器生效,配置一个 FieldType,制定使用 IKAnalyzer的分词规则,这个需要修改schema.xml文件,具体修改步骤如下:
-
修改
schema.xml文件$ cd /home/silhouette/solr-index/solr/collection1/conf $ vim schema.xml # 修改 Solr 的 schema.xml 文件,添加 FieldType # 1.添加IK分词器的相关配置 <!-- IKAnalyzer--> <fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> # 2. 配置业务域,type制定使用自定义的 FieldType <field name="item_title" type="text_ik" indexed="true" stored="true"/> <field name="item_sell_point" type="text_ik" indexed="true" stored="true"/> <field name="item_price" type="long" indexed="true" stored="true"/> <field name="item_image" type="string" indexed="false" stored="true" /> <field name="item_category_name" type="string" indexed="true" stored="true" /> <field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/> <copyField source="item_title" dest="item_keywords"/> <copyField source="item_sell_point" dest="item_keywords"/> <copyField source="item_category_name" dest="item_keywords"/>
重启tomcat,访问 solo 测试IK分词器是否生效。
二、SolrJ的使用
2.1 概述
SolrJ 是 Apache 官方提供的一套 Java 开发的,访问 Solr 服务的 API,通过这套 API 可 以让我们的程序与 Solr 服务产生交互,让我们的程序可以实现对 Solr 索引库的增删改查。
-
添加依赖:
<dependencies> <!-- Junit单元测试 --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <dependency> <groupId>org.apache.solr</groupId> <artifactId>solr-solrj</artifactId> <version>4.10.2</version> </dependency> <!-- Solr底层会使用到slf4j日志系统 --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.22</version> </dependency> <dependency> <groupId>commons-logging</groupId> <artifactId>commons-logging</artifactId> <version>1.2</version> </dependency> </dependencies>
2.2 使用 SolrJ 添加或修改索引库数据
-
创建索引-
以 Document 形式添加或修改数据
@Test public void createIndex() throws Exception{ //定义Solr的URL路径 String baseURL = "http://192.168.0.111:8080/solr/collection1"; //要使用SolrJ首先创建服务对象,Solr实际上是提供web服务,需啊哟创建web服务的对象,支持HTTP请求 HttpSolrServer server = new HttpSolrServer(baseURL); //添加索引,需要Document对象 SolrInputDocument document = new SolrInputDocument(); document.addField("id", "20"); document.addField("title", "今天星期二,是一周的第三天。"); //将Document添加到索引库 server.add(document); //提交请求 server.commit(); } -
使用注解和 JavaBean 添加或修改数据
@Test public void testInsertIndexByBean() throws Exception { //定义Solr的URL路径 String baseURL = "http://192.168.0.111:8080/solr/collection1"; //创建Java对象 Book book = new Book("12345", "Solr初识","silhouette","Solr 是一个独立的企业级搜索应用服务器"); HttpSolrServer httpSolrServer = new HttpSolrServer(baseURL); //将对象插入索引库 UpdateResponse updateResponse = httpSolrServer.addBean(book); int status = updateResponse.getStatus(); System.out.println(status); //提交 httpSolrServer.commit(); }
-
-
删除索引-
根据 ID 删除
@Test public void testDleteIndexById() throws Exception{ //定义Solr的URL路径 String baseURL = "http://192.168.0.111:8080/solr/collection1"; //要使用SolrJ首先创建服务对象,Solr实际上是提供web服务,需啊哟创建web服务的对象,支持HTTP请求 HttpSolrServer server = new HttpSolrServer(baseURL); //server.deleteById("10"); List<String> list = new ArrayList<String>(); list.add("10"); list.add("12"); //删除索引 server.deleteById(list); //提交请求 server.commit(); } -
通过制定条件删除
@Test public void testDleteIndexByQuery() throws Exception{ //定义Solr的URL路径 String baseURL = "http://192.168.0.111:8080/solr/collection1"; //要使用SolrJ首先创建服务对象,Solr实际上是提供web服务,需啊哟创建web服务的对象,支持HTTP请求 HttpSolrServer server = new HttpSolrServer(baseURL); //Solr提供的是web服务,在接收用户传递的参数是就是request参数 String query="title:solr"; //删除索引 server.deleteByQuery(query); //提交请求 server.commit(); }
-
-
查询索引-
以 Document 形式返回查询结果
@Test public void testQueryIndex() throws Exception{ //定义Solr的URL路径 String baseURL = "http://192.168.0.111:8080/solr/collection1"; //要使用SolrJ首先创建服务对象,Solr实际上是提供web服务,需啊哟创建web服务的对象,支持HTTP请求 HttpSolrServer server = new HttpSolrServer(baseURL); String query = "*:*"; //进行查询操作 SolrParams params = new SolrQuery(query ); QueryResponse queryResponse = server.query(params); SolrDocumentList results = queryResponse.getResults(); for (SolrDocument solrDocument : results) { String id = (String) solrDocument.get("id"); String name = (String) solrDocument.get("name"); System.out.println("id:"+id+" name:"+name); } //提交请求 server.commit(); } -
以 JavaBean 形式返回查询结果
@Test public void testQueryIndex() throws Exception{ //定义Solr的URL路径 String baseURL = "http://192.168.0.111:8080/solr/collection1"; //要使用SolrJ首先创建服务对象,Solr实际上是提供web服务,需啊哟创建web服务的对象,支持HTTP请求 HttpSolrServer server = new HttpSolrServer(baseURL); String query = "author:silhouette"; //进行查询操作 SolrParams params = new SolrQuery(query); QueryResponse queryResponse = server.query(params); List<Book> books = queryResponse.getBeans(Book.class); for (Book book : books) { System.out.println(book); } //提交请求 server.commit(); }注意:1.JavaBean的属性要和Solr界面管理展示的属性要一致,如果缺少字段则补上,如果属性不同,就修改JavaBean或者scheme.xml配置文件。
-
SolrQuery 对象的高级查询
-
匹配所有文档:*:* (通配符?和*:“*”表示匹配任意字符;“?”表示匹配出现的位置)
-
布尔操作:AND、OR 和 NOT 布尔操作(推荐使用大写,区分普通字段)
-
子表达式查询(子查询):可以使用“()”构造子查询。 比如:(query1 AND query2) OR(query3 AND query4)
-
相似度查询:
- 默认相似度查询:title:appla~ ,此时默认编辑距离是2。~表示模糊查询,默认编辑距离为2
- 指定编辑举例的相似度查询:对模糊查询可以设置编辑举例,可选 0~2 的整数。
-
范围查询(Range Query):Lucene 支持对数字、日期甚至文本的范围查询。结束的范 围可以使用“*”通配符。
- 日期范围(ISO-8601 时间 GMT):a_begin_date:[1990-01-01T00:00:00.000Z TO 1999-12-31T24:59:99.999Z]
- 数字:salary:[2000 TO *]
- 文本:entryNm:[a TO a]
-
日期匹配:YEAR, MONTH, DAY, DATE (synonymous with DAY) HOUR, MINUTE, SECOND, MILLISECOND, and MILLI (synonymous with MILLISECOND)可以被标志成 日期。
- r_event_date:[* TO NOW-2YEAR]:2 年前的现在这个时间
- r_event_date:[* TO NOW/DAY-2YEAR]:2 年前前一天的这个时间
@Test public void testQueryIndex() throws Exception{ //定义Solr的URL路径 String baseURL = "http://192.168.0.111:8080/solr/collection1"; //要使用SolrJ首先创建服务对象,Solr实际上是提供web服务,需啊哟创建web服务的对象,支持HTTP请求 HttpSolrServer server = new HttpSolrServer(baseURL); SolrParams params = new SolrQuery("description:战国 AND id:3"); QueryResponse queryResponse = server.query(params); List<Book> books = queryResponse.getBeans(Book.class); for (Book book : books) { System.out.println(book); } //提交请求 server.commit(); }
-
-
-
排序实现@Test public void testQueryIndex() throws Exception{ //定义Solr的URL路径 String baseURL = "http://192.168.0.111:8080/solr/collection1"; //要使用SolrJ首先创建服务对象,Solr实际上是提供web服务,需啊哟创建web服务的对象,支持HTTP请求 HttpSolrServer server = new HttpSolrServer(baseURL); String query = "author:*"; //进行查询操作 SolrParams params = new SolrQuery(query); params.addSort("id", ORDER.asc); QueryResponse queryResponse = server.query(params); List<Book> books = queryResponse.getBeans(Book.class); for (Book book : books) { System.out.println(book); } //提交请求 server.commit(); } -
分页实现@Test public void testQueryIndex() throws Exception{ //定义Solr的URL路径 String baseURL = "http://192.168.0.111:8080/solr/collection1"; //要使用SolrJ首先创建服务对象,Solr实际上是提供web服务,需啊哟创建web服务的对象,支持HTTP请求 HttpSolrServer server = new HttpSolrServer(baseURL); //要查询的页数 int pageNum = 2; //每页显示条数 int pageSize = 2; //当前页的起始条数 int start = (pageNum - 1) * pageSize; //当前页的结束条数 int end = start + pageSize; SolrQuery query = new SolrQuery("*:*"); //设置起始条数 query.setStart(start); //设置每页条数 query.setRows(pageSize); //进行查询操作 QueryResponse queryResponse = server.query(query); SolrDocumentList results = queryResponse.getResults(); System.out.println("当前第" + pageNum + "页,本页共" +results.size() + "条数据。"); for (SolrDocument solrDocument : results) { System.out.println(solrDocument.get("id")); System.out.println(solrDocument.get("title")); } //提交请求 server.commit(); } -
高亮实现@Test public void testQueryIndex() throws Exception{ //定义Solr的URL路径 String baseURL = "http://192.168.0.111:8080/solr/collection1"; //要使用SolrJ首先创建服务对象,Solr实际上是提供web服务,需啊哟创建web服务的对象,支持HTTP请求 HttpSolrServer server = new HttpSolrServer(baseURL); //定义查询条件 String query = "title:*"; //进行查询操作 SolrQuery params = new SolrQuery(query); //设置高亮 params.setHighlightSimplePre("<em>"); params.setHighlightSimplePost("</em>"); //设置高亮显示的字段 params.addHighlightField("title"); QueryResponse queryResponse = server.query(params); SolrDocumentList results = queryResponse.getResults(); //在map中首先使用每一条数据的id作为键,将数据作为值(只有高亮字段) //Map<String, List<String>>存放的是一条数据的所有高亮字段,键就是字段的名称,值就是高亮显示的数据 //List<String>里面就是经过处理的高亮的内容,主要是因为Solr中的字段可以存储多个值,对于单个数据而言,list的长度都为1 Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting(); System.out.println("找到了"+results.size()+"条记录"); //那么获取高亮数据可以获取对应的id,在指定高亮字段的名称,在获取list的第0个元素 for (SolrDocument solrDocument : results) { String id = solrDocument.get("id").toString(); String title = highlighting.get(id).get("title").get(0); System.out.println("id:"+id+"--- title:"+title); } //提交请求 server.commit(); } -
设置权重@Test public void testQueryIndex() throws Exception{ //定义Solr的URL路径 String baseURL = "http://192.168.0.111:8080/solr/collection1"; //要使用SolrJ首先创建服务对象,Solr实际上是提供web服务,需啊哟创建web服务的对象,支持HTTP请求 HttpSolrServer server = new HttpSolrServer(baseURL); SolrInputDocument doc = new SolrInputDocument(); //通过boost设置字段的权重 doc.addField("id", "20"); doc.addField("description", "Spring从入门到精通是一本好书",2.0f); server.add(doc); //提交请求 server.commit(); } @Test public void testCreateIndex() throws Exception { //定义Solr的URL路径 String baseURL = "http://192.168.0.111:8080/solr/collection1"; //要使用SolrJ首先创建服务对象,Solr实际上是提供web服务,需啊哟创建web服务的对象,支持HTTP请求 HttpSolrServer server = new HttpSolrServer(baseURL); SolrParams params = new SolrQuery("description:Spring"); QueryResponse queryResponse = server.query(params); SolrDocumentList results = queryResponse.getResults(); for (SolrDocument solrDocument : results) { System.out.println(solrDocument.get("id")+" : "+solrDocument.get("description")); } //提交请求 server.commit(); }